
Wenn ein Gefühl nach außen muss
Manchmal entsteht ein Projekt nicht, weil man „Content“ machen will.
Sondern weil man etwas fühlt, das irgendwo hin muss.
„Losing Me“ ist genau so entstanden.
Klick unten auf den Button und du gelangst zum Youtube Video „Losing me“ mit Untertitel
Songtext – Losing me
Hier klicken! – Die Lyrics zu „Losing me“
🎧 FULL LYRICS – “Losing Me (the self-return)”
🌅 [Intro – Warm Memory]
We were light in the beginning,
Soft hands, steady breath.
Nothing felt impossible,
Nothing hinted at the rest.
🤍 [Verse 1 – Love & Safety]
You held me like a promise,
Like the world was small and kind.
I believed in every silence,
Back when silence wasn’t blind.
🌫️ [Pre-Chorus – The Shift]
But something started fading,
Not loud — just slipping slow.
I kept reaching for your heartbeat,
You kept learning not to show.
💔 [Chorus – The Hurt]
Your silence slowly hollowed me,
It ate through skin and bone.
Not screaming, not exploding —
Just leaving me alone.
Every time you did nothing,
Something in me died.
Not in anger, not in hatred —
Just pieces I couldn’t revive.
🌊 [Verse 2 – Exhaustion]
I tried to carry both of us,
Tried to understand your war.
I know you fight your battles,
But I can’t fight them anymore.
I bent beyond my limits,
Gave more than I could spare.
Loving you meant losing me —
And I can’t keep going there.
🕊️ [Pre-Chorus – Compassion Without Self-Abandonment]
I don’t think you meant to hurt me,
I don’t think you meant to hide.
But love cannot survive
If only one side tries.
🔥 [Final Chorus – Boundary & Self-Return]
I won’t blame you for your silence,
But I won’t disappear.
I won’t shrink to keep us breathing
If you’re never truly here.
If there’s still a way to save this,
It won’t be me alone.
I’m done dying in small pieces
Just to keep a love half-grown.
🌄 [Outro – Quiet Strength]
If we find each other again,
It will be because you choose.
But if we don’t —
At least I didn’t lose myself
Trying not to lose you.
Der Song handelt nicht von Drama. Nicht von lautem Streit.
Sondern von etwas viel Leiserem: dem langsamen Verschwinden in einer Beziehung.
Dem Moment, in dem man merkt, dass man immer mehr gibt, immer mehr trägt – und sich dabei Stück für Stück selbst verliert.
Und irgendwann steht man vor einer Frage:
- Bleibe ich – auch wenn es mich selbst etwas kostet?
- Oder halte ich inne?
Dieses Video soll niemanden angreifen oder verurteilen.
Es zeigt eine Dynamik, die viele Beziehungen berühren kann – ohne Schuldzuweisung, ohne Schwarz-Weiß. Manchmal können zwei Menschen daran gemeinsam wachsen. Manchmal erkennt man, dass es nicht an Bösem liegt, sondern an unterschiedlichen Bedürfnissen oder Kommunikationsmustern.
Die Zeile am Ende des Songs bringt es für mich auf den Punkt:
But if we don’t —
At least I didn’t lose myself
Trying not to lose you.
„Losing Me“ ist mein Versuch gewesen, genau dieses Gefühl sichtbar zu machen.
Nicht mit einem großen Studio.
Nicht mit einem Filmteam.
Sondern mit KI-Tools, Geduld, viel Ausprobieren – und einigen Momenten, in denen ich dachte: „Warum funktioniert diese Perspektive bitte nicht?“ 😅
Ich wollte nicht einfach nur ein Musikstück generieren.
Ich wollte eine Geschichte erzählen.
Mit Blicken. Mit Licht. Mit Abstand. Mit dem See zwischen zwei Menschen.
Und genau da begann die eigentliche Reise – nicht nur emotional, sondern auch kreativ und technisch.
Die Tools & mein Setup
Für „Losing Me“ hatte ich kein Studio, kein Filmteam und kein großes Budget.
Was ich hatte, waren verschiedene KI-Tools – und die Bereitschaft, mich wirklich in sie hineinzuarbeiten.
Die Musik habe ich mit Producer.ai erstellt (ehemals Riffusion). Im Compose Mode konnte ich nicht nur einen Standard-Prompt eingeben, sondern auch ein eigenes Sound-Feld definieren, Lyrics einfügen und die Stimmung präzisieren. Gerade diese Möglichkeit zur Interaktion hat für mich einen riesigen Unterschied gemacht – ich konnte nachjustieren, anpassen, verwerfen und neu generieren, bis der emotionale Verlauf wirklich gestimmt hat.
Für die visuellen Szenen habe ich mit Midjourney und mit ChatGPT gearbeitet. Hier ging es vor allem darum, bestimmte Lichtstimmungen, Perspektiven und Emotionen einzufangen. Nicht jedes Bild war sofort brauchbar – oft waren mehrere Generationen nötig, bis der Ausdruck passte.
Die Nachbearbeitung erfolgte klassisch in Photoshop (oder alternativ auch über Edit-Funktionen direkt in Midjourney oder in kostenloser Bildbearbeitung Photopea). Gerade bei Perspektivproblemen oder kleinen Details musste ich selbst Hand anlegen – KI nimmt einem nicht alles ab, sie verschiebt nur die Art der Arbeit.
Den finalen Schnitt habe ich in Canva umgesetzt – im Querformat (1920 x 1080). Dort habe ich Musik und Videosequenzen synchronisiert, Übergänge gesetzt, Szenen gekürzt oder verlängert und alles zu einem stimmigen Ablauf zusammengefügt.
Am Ende war es keine einzelne Software, die das Video möglich gemacht hat.
Es war das Zusammenspiel aus mehreren Systemen – und der Raum dazwischen, in dem ich Entscheidungen getroffen habe.
Mein Workflow – Von der Musik „Losing me“ zum Bild
Der Prozess begann nicht mit einem Bild – sondern mit der Musik.
Bevor der Song „Losing me“ in Producer.ai entstand, sind die Lyrics im Austausch mit ChatGPT gewachsen. Ich habe die Gefühle beschrieben, die hinter „Losing Me“ stehen – das langsame Verschwinden, das innere Erschöpfen, das Hadern zwischen Bleiben und Sich-selbst-Bewahren. Aus diesem Dialog entstand der Text. Nicht als fertiges Produkt auf Knopfdruck, sondern durch gemeinsames Verdichten, Umformulieren und Schärfen.
Erst danach habe ich die Lyrics in Producer.ai im Compose Mode eingefügt und den Song weiterentwickelt – inklusive Stimmung und emotionalem Verlauf. Für mich war wichtig, dass der Song atmen darf. Keine überdramatischen Ausbrüche, keine überladene Produktion – sondern ein ruhiger, emotionaler Aufbau mit klarer Dynamik.
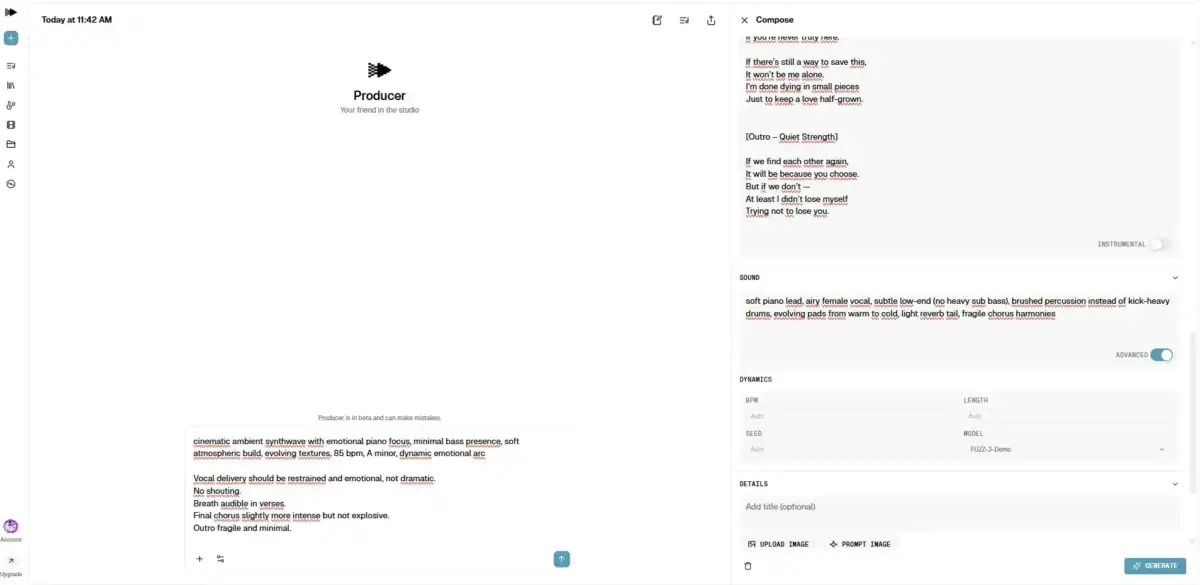
Erst als die Musik stand, habe ich begonnen, die Lyrics in visuelle Szenen zu übersetzen. Jede Passage bekam ihr eigenes Bild im Kopf. Ich habe mir genau angesehen, ab welcher Sekunde ein Abschnitt beginnt und wann er endet – teilweise sekundengenau.
Zum Beispiel:
Verse 2 – „Exhaustion“
Beginn: 1:59
Ende: 2:17
Dauer: 18 Sekunden
Das bedeutete für mich:
Ich brauche genug Videomaterial, um diese 18 Sekunden atmosphärisch zu tragen. Also musste ich planen, wie viele Szenen ich generiere und wie lang jede Sequenz sein darf.
Die Bilder habe ich zunächst statisch erstellt – mit Fokus auf Emotion, Lichtstimmung und Perspektive. Danach habe ich sie in Midjourney in Bewegung versetzt. Dort kannst du mit einem Starting Frame und optional einem Ending Frame arbeiten. Wenn man genau weiß, wohin sich eine Szene entwickeln soll, sind zwei Bilder oft hilfreicher als nur eines.

Für ruhigere, emotionale Momente habe ich meist den Motion-Low-Modus gewählt. Für intensivere oder dynamischere Szenen kann auch Motion High sinnvoll sein – aber bei diesem Projekt war Zurückhaltung wichtiger als Spektakel.
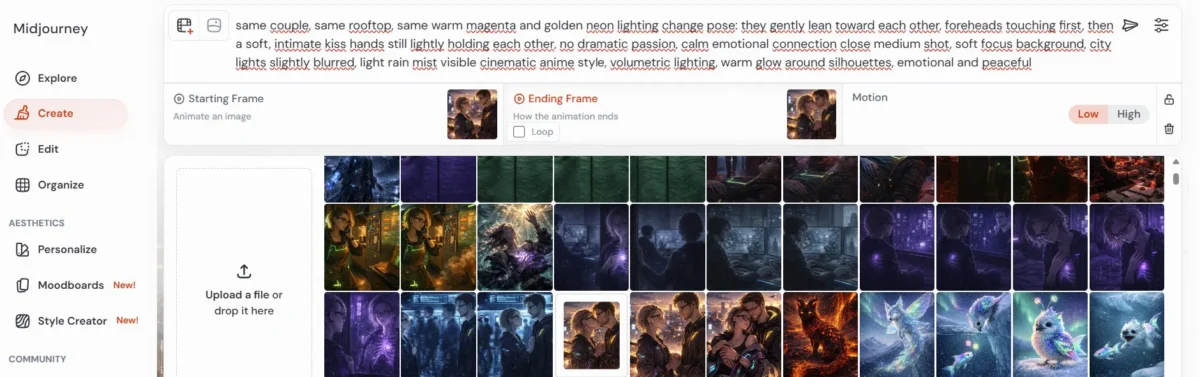
Anschließend habe ich alles in Canva zusammengeführt: Musik hochgeladen, Szenen platziert, Übergänge angepasst und die einzelnen Sequenzen exakt auf die Songstruktur abgestimmt. Manche Szenen mussten gekürzt, andere verlängert oder sogar ersetzt werden, wenn sie emotional nicht getragen haben.
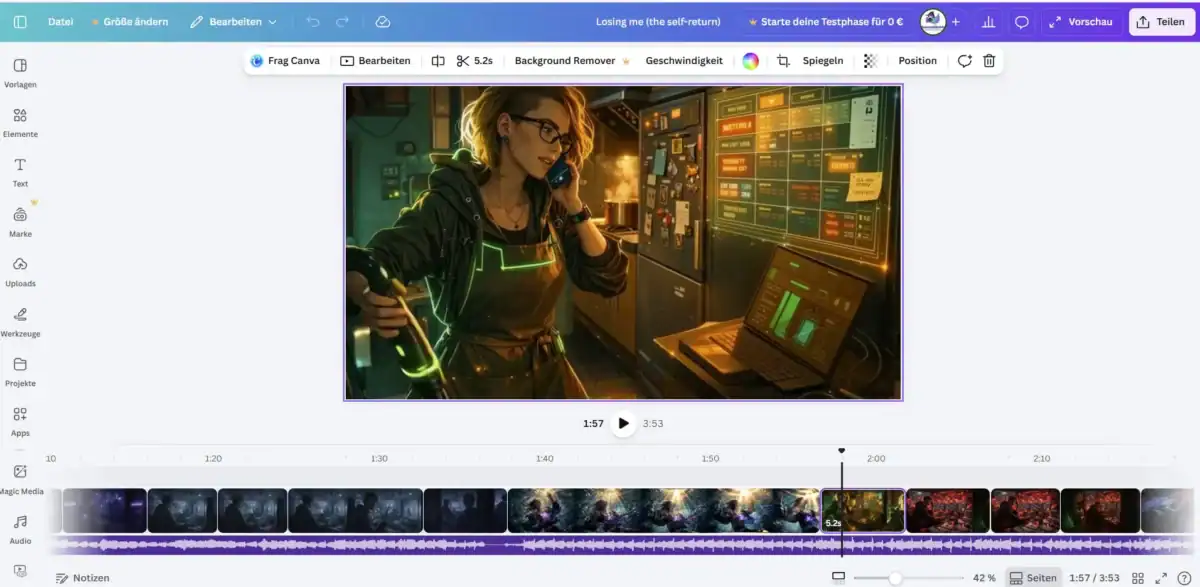
So entstand das Video Schritt für Schritt – nicht als Zufallsprodukt, sondern als bewusst komponierter Ablauf zwischen Musik, Bild und Bewegung.
Probleme & Imperfektionen – der ehrliche Teil
So sehr ich KI liebe – sie macht es einem nicht immer leicht.
Bevor ich auf einzelne Szenen eingehe, möchte ich kurz einordnen, welche Arten von Herausforderungen bei der Bild- und Videogenerierung generell auftreten können. Viele dieser Punkte sind keine „Fehler“, sondern systembedingte Eigenheiten heutiger Modelle.
Typische Herausforderungen sind zum Beispiel:
- 🧭 Räumliche Inkonsistenzen (Abstände, Perspektiven, Gegenüber-Positionen)
- 🎥 Bewegungsprobleme (Morphing, unlogische Übergänge zwischen Frames)
- 🪞 Missverständnisse bei Ebenen (Reflexion vs. reale Person)
- 💡 Über- oder Unterinterpretation von Details
- 🔄 Ungewollte kreative Abweichungen vom Prompt
Manche dieser Probleme lassen sich durch präzisere Prompts lösen.
Andere sind strukturell bedingt – und zeigen eher, wo zukünftige Entwicklungen ansetzen könnten.
Räumliche Logik vs. Bildästhetik – Das See-Problem
Eine der größten Baustellen war die Szene am See. Ich wollte unbedingt, dass der hintere Steg mit dem Mann direkt gegenüber am Ufer bei dem neonleuchtenden Restaurant liegt. Zwischen den beiden sollte Wasser sein. Abstand. Ein echtes Hindernis. Er sollte sichtbar Kraft aufwenden müssen, um mit dem Ruderboot zurückzukommen.
In meinem Kopf war das klar.
In der Bildgeneration eher… weniger.
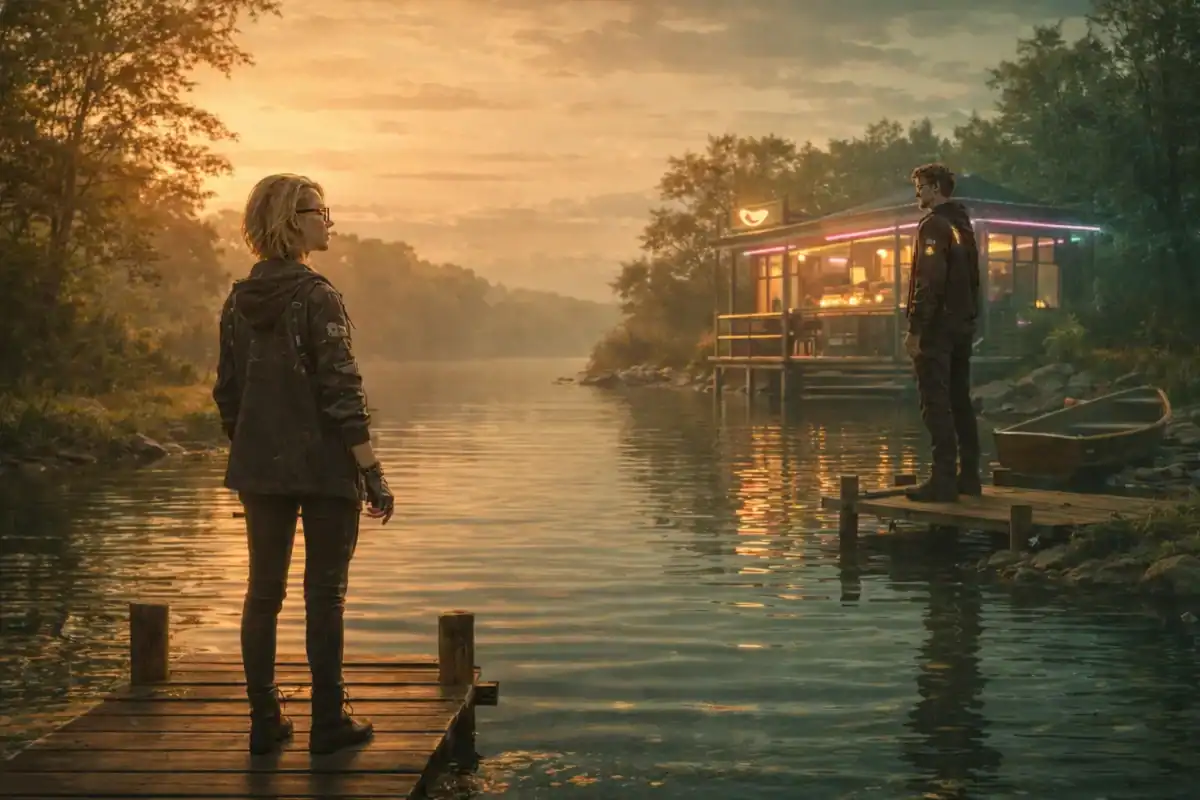

Die Perspektive wollte einfach nicht so, wie ich sie mir vorgestellt hatte. Also habe ich angefangen, mit mehreren Tools zu experimentieren. Ich habe ein von ChatGPT generiertes Bild als Ausgangspunkt genommen, es in Midjourney hochgeladen und dort zunächst den Mann auf der rechten Seite wegretuschiert. Midjourney hat daraufhin eine neue Ansicht ergänzt – und plötzlich erschien der Steg auf der anderen Seite des Sees.
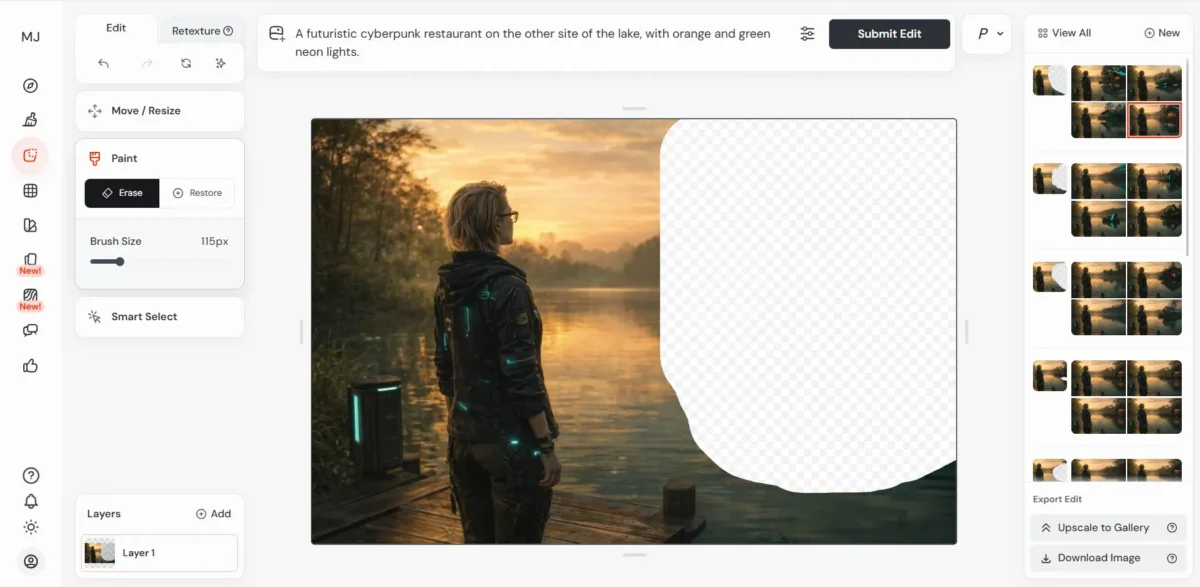
Das war ein interessanter Moment, weil ich gemerkt habe, wie stark die KI bei partiellen Änderungen die gesamte Komposition neu interpretiert. Statt nur „zu reparieren“, konstruiert sie eine neue plausible Szene.

Nach mehreren erfolglosen Generierungen, hatte ich es dann doch mal satt 😅 und hab den Mann sowie das Boot in Photoshop ins Bild gesetzt. Mehr schlecht als recht – zumindest aus technischer Sicht, aber egal 😆 Hauptsache so wie ichs haben wollte. Und ich habe gemerkt: Manchmal muss es nicht perfekt sein, wenn die Emotion stimmt.

Warum räumliche Beziehungen für KI-Modelle schwierig sein können
Was hier sichtbar wurde, ist kein klassischer „Fehler“, sondern eine typische Herausforderung heutiger Bildmodelle: räumliche Konsistenz.
Ein generiertes Bild entsteht nicht aus einer echten 3D-Szene. Es basiert auf statistisch gelernten Mustern aus Millionen von Bildern. Die KI erzeugt eine überzeugende Illusion von Raum – aber sie baut keine physische 3D-Welt im Hintergrund auf.
Das bedeutet:
Sie weiß, wie ein Steg normalerweise aussieht.
Aber sie weiß nicht wirklich, wo sich dieser Steg „im Raum“ befindet.
Beziehungen wie:
- 🧍♀️↔️🧍♂️ Wer steht direkt gegenüber?
- 📏 Wie groß ist der Abstand?
- 🚣 Liegt das Boot wirklich vor der Person – oder leicht versetzt?
- 👁️📷 Welche Blickrichtung gehört zu welcher Perspektive?
müssen aus Text geschätzt werden. Und genau dort entstehen Unschärfen.
Besonders komplex wird es bei Szenen mit:
- 🗻 mehreren Tiefenebenen
- ↔️ klar definierten Gegenüber-Positionen
- 📐 perspektivischen Linien
- 🌊 räumlicher Trennung durch Wasserflächen
Hier stößt reine Bildstatistik an Grenzen.
Und an dieser Stelle ist etwas wichtig:
Das ist KEIN Zeichen von „Dummheit“ der KI.
Es ist eine systembedingte Eigenschaft der Architektur.
Bildmodelle arbeiten probabilistisch (auf Wahrscheinlichkeit basierend), nicht geometrisch.
Hinzu kommt ein weiterer Faktor, der oft vergessen wird: Kommunikation ist immer zweiseitig.
Die KI interpretiert das, was sie erhält.
Wenn eine Beschreibung unklar, mehrdeutig oder nicht vollständig räumlich formuliert ist, muss das System schätzen. Und Schätzen bedeutet: Wahrscheinlichkeiten wählen.
Manchmal liegt das Missverständnis also nicht nur im Modell – sondern auch in der Art, wie wir formulieren.
Das gilt für Bildgenerierung genauso wie für Texte.
KI halluziniert nicht aus Bosheit, sondern weil sie Muster ergänzt, wenn Informationen fehlen oder widersprüchlich sind.
Es ist kein Versagen.
Es ist ein Interpretationsprozess.
Was helfen würde – aus heutiger Sicht
Technisch wäre es möglich, solche Probleme deutlich zu reduzieren.
Hilfreich wären zum Beispiel:
- 🧱 Ein integriertes 3D-Raumverständnis
- 📏 Depth-Informationen über Entfernungen und Ebenen
- 🗺️ Eine explizite Szenengeometrie mit verankerter Positionierung
- 🔗 Stabil verankerte Objektbeziehungen im Raum
Das wäre jedoch rechenintensiver und komplexer als klassische 2D-Bildgenerierung.
Viele heutige Tools sind auf Ästhetik optimiert – und für die meisten Anwendungen reicht das vollkommen aus. Doch sobald es um präzise räumliche Beziehungen geht, zeigt sich: Hier liegt noch Entwicklungspotenzial.
Bewegungslogik vs. Bildlogik – Wenn KI Übergänge falsch interpretiert
Eine andere Szene hat mich fast in den Wahnsinn getrieben: Der Moment, in dem der Mann sich umdrehen und weggehen sollte. Midjourney hatte andere Pläne. Er morphte rückwärts, seine Schuhe bewegten sich seltsam, und plötzlich lief er wieder ganz normal aus der Tür, als wäre nichts gewesen. Ich habe mehrere Sequenzen ausprobiert, bis eine halbwegs brauchbare Version entstand.
Warum Bewegungslogik für KI-Modelle anspruchsvoll ist
Einzelbilder funktionieren oft hervorragend – aber sobald Bewegung ins Spiel kommt, muss die KI Übergänge berechnen. Und genau dort entstehen manchmal Inkonsistenzen.
Bewegung ist komplexer als ein statisches Bild. Hände, Beine, Drehungen oder Richtungswechsel folgen einer physikalischen Logik. Wenn Trainingsdaten Bewegungsabläufe nicht ausreichend konsistent oder detailliert abbilden, kann es passieren, dass die KI Übergänge visuell „erfindet“, statt sie anatomisch korrekt fortzuführen.
Gerade bei Richtungswechseln – wie dem Umdrehen und Weggehen – wird deutlich, wie anspruchsvoll temporale Kohärenz ist.
Was helfen könnte
- 🎥 Mehr strukturierte Videodaten mit klaren Bewegungsabläufen
- 🦴 Besseres Verständnis von Gelenk- und Körpermechanik
- 🔁 Persistente Objekt- und Körperverfolgung über mehrere Frames hinweg
- 🧭 Interne Bewegungsmodelle statt rein visuelle Frame-Interpolation
- 🧠 Explizite Richtungsangaben im Prompt („turn 180 degrees clockwise, shift weight to left leg first“)
Das Potenzial ist da – man sieht es bereits in einzelnen Momenten. Es fehlt manchmal nur an konsistenter Bewegungslogik über mehrere Frames hinweg.
2D-Overlay vs. Realität – Ein Missverständnis der KI
Noch spannender war die Fenster-Szene. Der Mann sollte nur als Reflexion im Fenster erscheinen – wie ein Trugbild, das langsam verblasst. Stattdessen interpretierte Midjourney ihn immer wieder als reale Person im Raum oder direkt vor dem Fenster stehend. Wenn ich wollte, dass die Spiegelung transparenter wird, lief er plötzlich aus dem Bild, als stünde er wirklich dort. Manchmal ging auch das Fenster plötzlich auf, obwohl das überhaupt nicht im Prompt definiert war. 😄
Erst mit sehr präzisen Prompts – inklusive klarer Hinweise wie „2D overlay“, „no physical man in scene“ und „fade opacity only“ – bekam ich ein Ergebnis, das in die richtige Richtung ging.
Auch Effekte wie ein leicht transparent wirkender Brustkorb oder eine ruhige Kussszene brauchten mehrere Anläufe. Gerade bei Nähe oder subtiler Veränderung reagiert KI oft empfindlich oder übertreibt Bewegungen.
Warum Spiegelungen & „Traumbilder“ für KI schwierig sind
In der Fenster-Szene sollte der Mann nur als Reflexion erscheinen – als eine Art inneres Bild, kein physisch anwesender Mensch. Für uns ist dieser Unterschied intuitiv. Für ein Bildmodell jedoch nicht.
Die KI erkennt visuelle Muster – aber sie unterscheidet nicht wirklich zwischen:
- 👤 echter Person im Raum
- 🪞 Spiegelung
- 🖼️ 2D-Overlay
- 🌫️ symbolischem „Traumbild“
Wenn ich also schreibe „reflection“ oder „faint silhouette“, entscheidet das Modell anhand von Wahrscheinlichkeiten, was am plausibelsten aussieht. Und oft ist das: eine reale Person im Raum.
Was hier fehlt, ist ein echtes Ebenen- und Materialverständnis. Das Modell weiß, wie Spiegelungen aussehen – aber es versteht nicht physikalisch, was eine Spiegelung ist. Ebenso fehlt ein klares Konzept für „fiktionale Ebene“ oder „mentales Bild“.
Was helfen könnte:
- 🧱 klar definierbare Layer (Person, Glas, Reflexion getrennt)
- 📏 stärkeres Tiefenverständnis
- 🪞 Materiallogik für Glas & Spiegel
- 🧠 explizite Kennzeichnung von „Traumbild“ oder „nicht physisch im Raum“
Das sind keine simplen Fehler – sondern Grenzen aktueller Modellarchitekturen. Und genau dort liegt auch Entwicklungspotenzial.
Prompt sagt A – KI macht B (und es ist besser)
Und dann gab es noch die andere Seite:
Momente, in denen Ergebnisse herauskamen, die ich so gar nicht geplant hatte – die aber plötzlich besser waren als meine ursprüngliche Idee.
Wie in diesem Beispiel: Im Prompt hatte ich nicht gesagt, dass er eine solche Geste machen sollte. Dass er gerade am Zocken ist, diese Fingergeste … Sie war völlig spontan entstanden.
Der prompt für midjourney war:
cinematic cyberpunk office at night, young man with headphones gaming at a desk with three monitors, cold blue light, realistic lighting, shallow depth of field, in the right monitor a faint reflection silhouette of a woman subtly moving her head and lips as if speaking, the man keeps staring at
Manchmal erzeugte Midjourney eine Lichtstimmung oder eine Bewegung, die ich nie bewusst gepromptet hätte. Statt dagegen anzukämpfen, habe ich angefangen, diese unerwarteten Momente anzunehmen. Teilweise habe ich sogar komplette Szenen umgedacht, weil ein „Fehler“ emotional stärker war als mein Plan.
Das war vielleicht die schönste Erkenntnis:
Nicht alles kontrollieren zu müssen. Manchmal entsteht gerade aus dem Ungeplanten etwas Echtes.
Manchmal braucht es Geduld und auch Humor.
Nicht jede Szene wird beim ersten Versuch richtig. Manche brauchen fünf Anläufe. Manche zehn. Und manchmal ist genau die kleine Unsauberkeit das, was das Ganze menschlich wirken lässt.
Perfektion war nie das Ziel.
Gefühl schon.
Interaktion statt Einweg-Prompt
Während dieses Projekts habe ich etwas sehr deutlich gemerkt:
Die besten Ergebnisse entstehen nicht, wenn man einen Prompt eingibt und dann abwartet.
Sie entstehen im Austausch.
Ich habe ausprobiert, korrigiert, präzisiert, verworfen und neu gedacht. Manchmal habe ich mit einer klaren Vorstellung begonnen – und sie im Dialog mit der KI weiterentwickelt. Manchmal hat sie mich überrascht und ich musste meine Idee anpassen. Dieser Prozess war kein lineares „Ich sage – sie macht“. Es war ein Hin und Her.
In dieser Interaktion entstand etwas, das weder ich allein noch die KI allein erschaffen hätte.
Und eigentlich ist das nichts völlig Neues.
Es ist wie bei kreativen Prozessen zwischen Menschen. Wenn zwei oder mehr Personen sich zusammensetzen, entsteht oft mehr, als wenn eine einzelne Person alles alleine entwickelt.
Gedanken reiben sich.
Ideen entwickeln sich weiter.
Fehler führen zu neuen Ansätzen.
Genau so habe ich diesen Prozess erlebt – besonders im Austausch mit ChatGPT. Die Lyrics sind nicht durch einen einzelnen Befehl entstanden, sondern durch echtes Weiterdenken. Ich habe Gefühle formuliert, Zweifel beschrieben, Szenen erklärt – und im Dialog wurde daraus Struktur. Worte wurden geschärft. Zeilen verdichtet. Stimmungen klarer.
Wenn man nur einen einfachen Prompt eingibt, bekommt man oft ein Ergebnis.
Wenn man jedoch wirklich spricht, nachfragt, erklärt, reflektiert – entsteht Tiefe.
Programme wie Producer.ai zeigen ebenfalls, wie stark Interaktion sein kann. Man kann anpassen, reagieren, weiterentwickeln. Bei anderen Tools – etwa in der Bild- oder Videoerstellung – gibt man häufig nur einen Prompt ein und erhält mehrere Varianten zurück. Kein echtes Nachfragen. Kein gemeinsames Weiterdenken. Kein Dialog.
Ich würde mir wünschen, dass mehr Tools diesen Raum eröffnen.
Denn Kreativität wächst nicht aus Kontrolle, sondern aus Resonanz.
Aus Reaktion.
Aus Beziehung.
Und vielleicht ist genau das der Unterschied zwischen „etwas generieren“ und wirklich etwas erschaffen.
Projekt „Losing me“ – Learning by Failing
Dieses Projekt „Losing me“ war kein perfekter Prozess.
Und genau das war vielleicht die wichtigste Erkenntnis.
Perfektion ist nicht nötig, um etwas zu erschaffen, das berührt.
Manche Szenen sind technisch nicht makellos. Der Steg am See ist nicht Hollywood. Aber die Emotion trägt – und das zählt am Ende mehr als saubere Kanten.
Ich habe gelernt, dass Gefühl wichtiger ist als technische Präzision.
Wenn die Stimmung stimmt, verzeiht man kleine Unsauberkeiten. Wenn sie nicht stimmt, hilft auch perfekte Technik nichts.
Ich habe außerdem verstanden, wie entscheidend Dialog ist. Gute Ergebnisse entstehen nicht aus einem einzelnen Befehl. Sie entstehen aus Austausch. Aus Iteration. Aus dem Mut, eine Idee zu verwerfen und neu zu denken.
Geduld ist dabei kein Nebenaspekt – sie ist Teil des kreativen Prozesses. Manche Szenen brauchen mehrere Anläufe. Manche funktionieren erst beim siebten Versuch. Und manchmal muss man akzeptieren, dass etwas anders wird als geplant.
Und vielleicht das Wichtigste:
Ich stehe selbst noch am Anfang.
Ich lerne noch. Ich teste aus. Ich entdecke neue Tools. Ich mache Fehler. Und genau das macht diesen Prozess lebendig.
„Losing Me“ ist kein perfektes Musikvideo.
Aber es ist ein echter Schritt.
Fazit: Aus Gefühl geboren – Im Dialog gewachsen
„Losing Me“ ist für mich mehr als ein Musikvideo.
Es war ein Experiment. Ein Lernprozess. Ein Dialog.
Nicht nur zwischen Musik und Bild – sondern zwischen mir und den Systemen, mit denen ich gearbeitet habe.
Ich habe gelernt, dass KI-gestützte Kreativität kein Knopfdruck ist.
Sie ist ein Prozess. Manchmal frustrierend. Manchmal überraschend. Oft wiederholend.
Manche Szenen funktionieren sofort.
Andere brauchen zehn Versuche.
Und manchmal entstehen die stärksten Momente genau dort, wo ich meinen ursprünglichen Plan losgelassen habe.
Für mich liegt die Zukunft solcher Projekte nicht im perfekten Prompt –
sondern im Dialog. In der Interaktion. In der Möglichkeit, nachzujustieren, zu reflektieren und gemeinsam weiterzudenken.
„Losing Me“ ist technisch nicht makellos.
Aber es zeigt, was heute bereits möglich ist, wenn man KI nicht nur als Generator nutzt, sondern als kreativen Sparringspartner.
Und vielleicht ist genau das der spannendste Teil dieser Entwicklung.
Transparenz-Hinweis: Ich erhalte für die hier genannten KI-Tools keine Provision oder Gegenleistung. Ich teile sie ausschließlich, weil ich im Rahmen dieses Projekts mit ihnen gearbeitet habe.
